Final GSoC Report
Aug 10, 2018 17:44 · 1413 words · 7 minute read
The objective of this project was to bring about a speedup in the PracMLN project. This was to be achieved by converting Python code to Cython.
Initial Proposal
At first the project was limited to adding typing information to variables and, to convert just the inference and logic modules to Cython. The initial proposal I had submitted proposed to do this by converting the .py files in the inference and learning directories to corresponding .pyx files. These are emphasized below, amongst a tree of all PracMLN files.
New Goals
This approach didn’t turn out to be very useful. There was very little scope for adding type information, and speedup obtained was negligible. Upon discussing the issue with Daniel, the focus of the project was changed. I now tried to optimise just one inference algorithm: EnumerationAsk, instead of all the learning and all the inference algorithms in PracMLN. The files that were eventually converted to cython over the course of the project are emphasized in the file tree below.
PracMLN ├── __init__.py ├── libpracmln.py ├── logic │ ├── common.py │ ├── fol.py │ ├── fuzzy.py │ ├── grammar.py │ ├── __init__.py │ └── sat.py ├── mln │ ├── base.py │ ├── constants.py │ ├── database.py │ ├── errors.py │ ├── grounding │ │ ├── bpll.py │ │ ├── common.py │ │ ├── default.py │ │ ├── fastconj.py │ │ └── __init__.py │ ├── inference │ │ ├── exact.py │ │ ├── gibbs.py │ │ ├── infer.py │ │ ├── __init__.py │ │ ├── ipfpm.py │ │ ├── maxwalk.py │ │ ├── mcmc.py │ │ ├── mcsat.py │ │ └── wcspinfer.py │ ├── __init__.py │ ├── learning │ │ ├── bpll.py │ │ ├── cll.py │ │ ├── common.py │ │ ├── __init__.py │ │ ├── ll.py │ │ ├── multidb.py │ │ ├── optimize.py │ │ └── softeval.py │ ├── methods.py │ ├── mlnpreds.py │ ├── mrf.py │ ├── mrfvars.py │ └── util.py ├── mlnlearn.py ├── mlnquery.py ├── test.py ├── utils │ ├── clustering.py │ ├── config.py │ ├── eval.py │ ├── evalSeqLabels.py │ ├── graphml.py │ ├── __init__.py │ ├── latexmath2png.py │ ├── locs.py │ ├── multicore.py │ ├── plot.py │ ├── pmml2graphml.py │ ├── project.py │ ├── sortedcoll.py │ ├── undo.py │ ├── visualization.py │ └── widgets.py ├── _version -> ../../_version ├── wcsp │ ├── __init__.py │ └── wcsp.py └── xval.pyPracMLN ├── __init__.py ├── libpracmln.py ├── logic │ ├── common.pxd │ ├── common.pyx │ ├── fol.pxd │ ├── fol.pyx │ ├── fuzzy.pxd │ ├── fuzzy.pyx │ ├── grammar.py │ ├── __init__.py │ ├── sat.py │ └── setup.py ├── mln │ ├── base.pxd │ ├── base.pyx │ ├── constants.py │ ├── database.py │ ├── errors.py │ ├── grounding │ │ ├── bpll.py │ │ ├── common.py │ │ ├── default.pxd │ │ ├── default.pyx │ │ ├── fastconj.py │ │ ├── __init__.py │ │ └── setup.py │ ├── inference │ │ ├── exact.pyx │ │ ├── gibbs.pyx │ │ ├── infer.pxd │ │ ├── infer.pyx │ │ ├── __init__.py │ │ ├── ipfpm.pyx │ │ ├── maxwalk.pyx │ │ ├── mcmc.pyx │ │ ├── mcsat.pyx │ │ ├── pracmln │ │ ├── setup.py │ │ └── wcspinfer.pyx │ ├── __init__.py │ ├── learning │ │ ├── bpll.py │ │ ├── cll.py │ │ ├── common.py │ │ ├── __init__.py │ │ ├── ll.py │ │ ├── multidb.py │ │ ├── optimize.py │ │ └── softeval.py │ ├── methods.py │ ├── mlnpreds.pxd │ ├── mlnpreds.pyx │ ├── mrf.pxd │ ├── mrf.pyx │ ├── mrfvars.pxd │ ├── mrfvars.pyx │ ├── setup.py │ ├── util.pxd │ └── util.pyx ├── mlnlearn.py ├── mlnquery.py ├── test.py ├── utils │ ├── clustering.py │ ├── config.py │ ├── eval.py │ ├── evalSeqLabels.py │ ├── graphml.py │ ├── __init__.py │ ├── latexmath2png.py │ ├── locs.py │ ├── multicore.py │ ├── plot.py │ ├── pmml2graphml.py │ ├── project.py │ ├── sortedcoll.py │ ├── undo.py │ ├── visualization.py │ └── widgets.py ├── _version -> ../../_version ├── wcsp │ ├── __init__.py │ └── wcsp.py └── xval.py
Work Done
I worked on the gsoc18-cython branch of my fork of the original pracmln repository. Over the course of the summer (excluding abandoned and experimental work), 39 commits were added to this branch, starting from python3 exact.py -> exact.pyx (797706a), up to add links (8e92f86).
A more technical desription of my work can be obtained by perusing the other posts on this blog, which document my weekly progress. Here is a list of posts, in chronological order, with a short synopsis of each.
- Welcome: Overview of GSoC, IAI, and PracMLN, along with my project abstract and proposal.
- PracMLN and Markov Logic Networks: Very brief introduction to MLNs, Python, and Cython.
- MLN Inference: Understanding PracMLN, and setting it up for development.
- EnumerationAsk: Cython extension types, and
exact.pyxdependencies, errors, and solutions. - The Logic Module: Complications with Cythonising the
logicmodule, and their resolution. - A Review: Mid-project overview of work done.
- Profiling: Notes on profiling Cython code, with an emphasis on PracMLN.
- The First Optimisations: Description of PracMLN bottlenecks, and possbile optimisation workflows.
- Speeding Up PracMLN: Profound Cython interventions and their effects on PracMLN performance.
- Wrapping Up: Miscellaneous work, restoration of functionality, and final code edits.
- Final GSoC Report: Report created to maintain compliance with Google guidelines.
Additionally, I have also simultaneously developed some rudimentory testing scripts that might be of some use to future developers. These can be found in my PracTests repository.
Demo
I have created a small demonstration to show the results of the work done this summer. This is adapted from the PracTests repository itself. It contains the following materials:
- Complete: A complete test of all learning and inference algorithms currently implemented in PracMLN. Uses a tiny version of the smokers MLN.
- EnumerationAsk: A larger test, but of only the EnumerationAsk inference algorithm. Used to measurably demonstrate the progress made over the summer.
- requirements.txt: Helper file to direct
pipto install all dependencies to run the demo scripts (ie. typical PracMLN requirements + Cython).
Here are the instructions to set up PracMLN and download the demo materials, to replicate the results:
After running the above setup commands, the scripts can be run to give:
We can now tabulate the data from this experiment.
| PracMLN (pure python) |
PracMLN (optimised cython) |
|
|---|---|---|
| Enumeration-Ask | 0.36s | 0.16s |
| All Inference and Learning Algorithms | 2.76s | 1.97s |
The outcomes of the project can thus be easily seen from this data.
Profiles
I have uploaded the cProfile outputs of a sample run of PracMLN in both pure python and optimised cython. These can be analysed by enthusiasts using pStats, cprofilev, snakeviz, or other profile analysers.
Here are screenshots of the “icicle” analysis of these files via snakeviz.
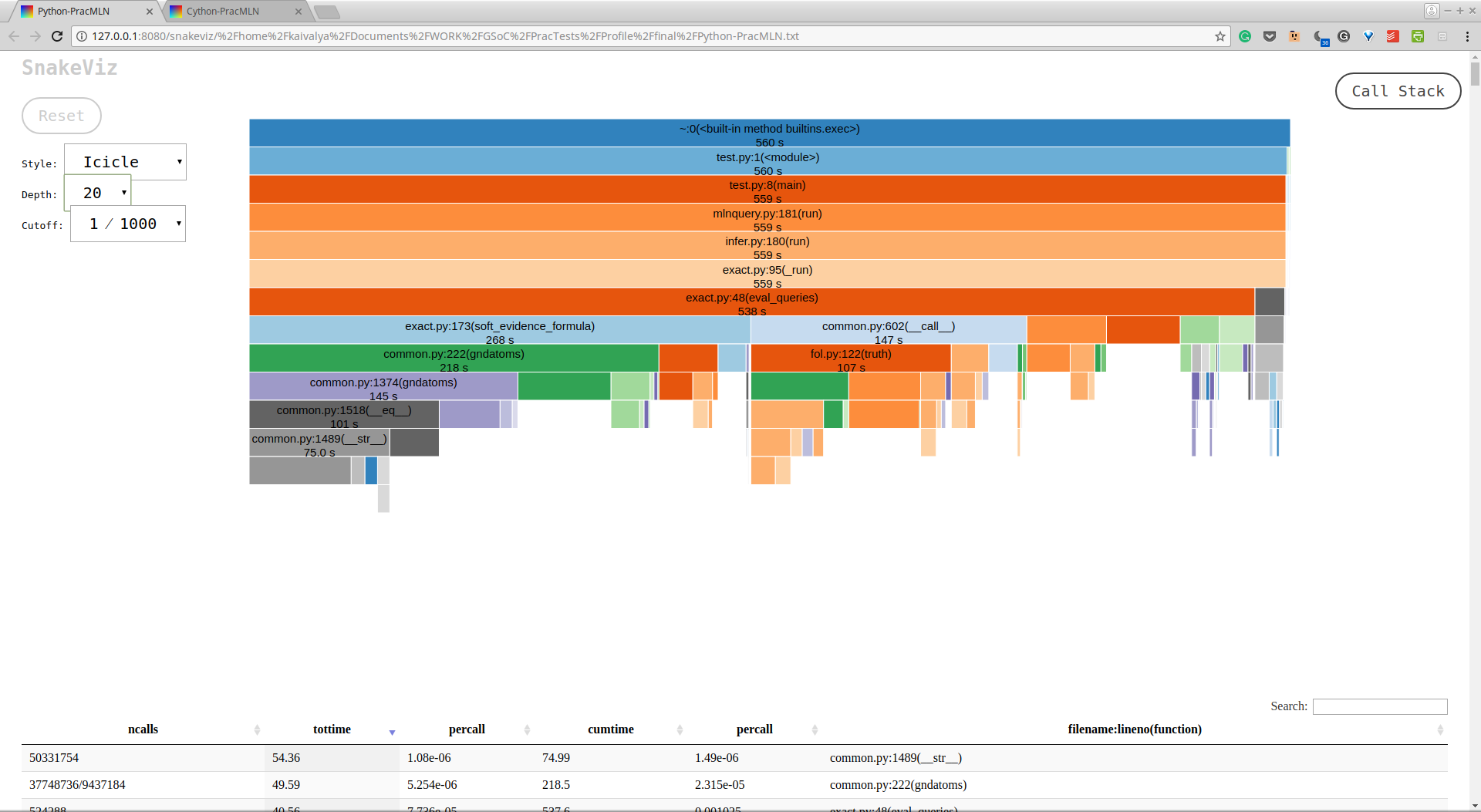
Profile of Pure Python PracMLN
The pure python version above took 560 seconds to execute, whereas the sped up cython version below ran in just 373 seconds.
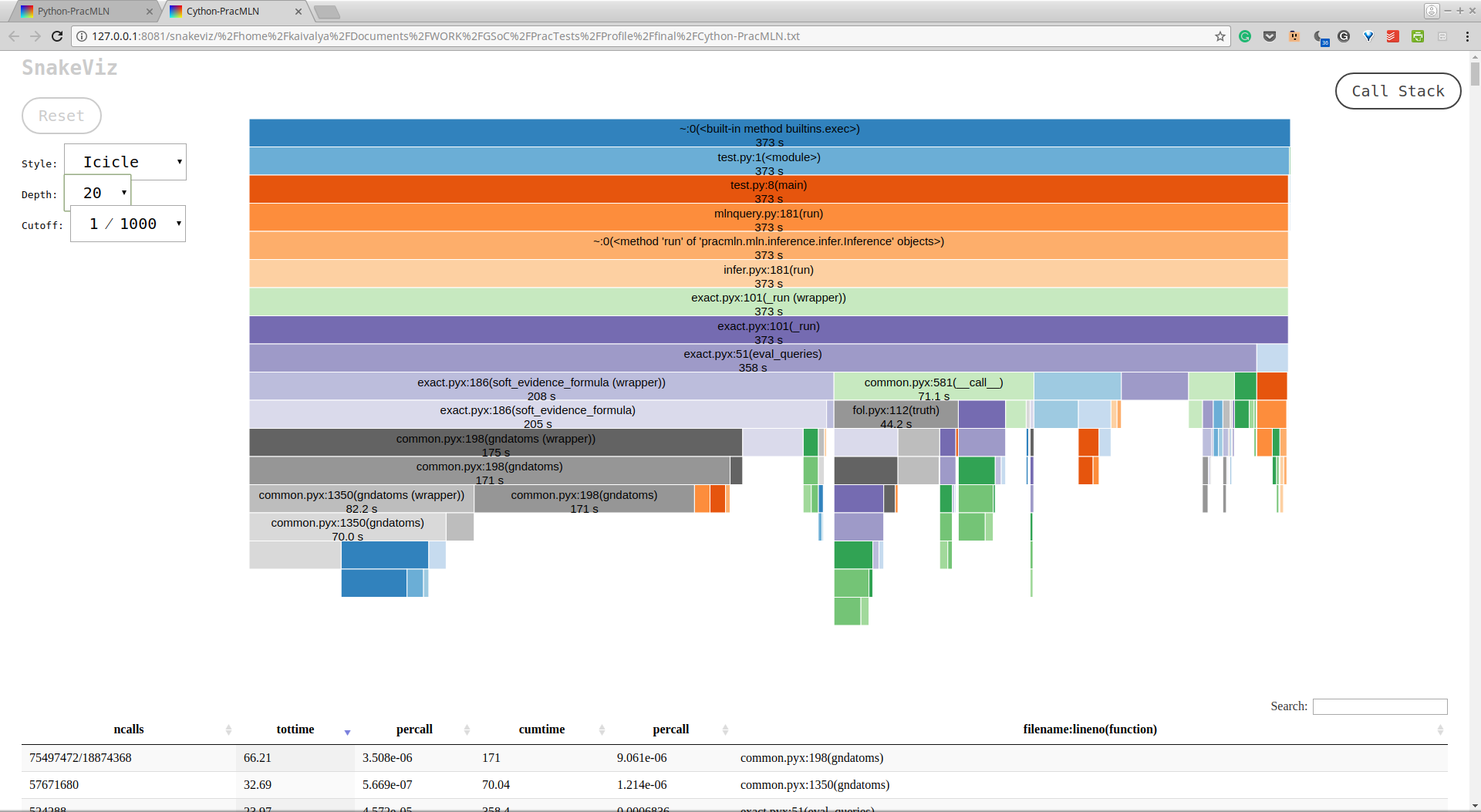
Profile of Optimised Cython PracMLN
Final Status
The code is functional, compiles correctly, and runs out of the box (as-is), with functionality identical to that of the master branch. There is a speed gain of about 40% when using the EnumerationAsk algorithm, and about 30% overall.
Future Work
Only the EnumerationAsk algorithm has been optimised for performance, and a lot of work remains to be done. Of these, my yet-to-be-finished work on _evidence and truth described in the previous blog post is arguably the most important.
This blog is perhaps a good starting point for future contributors to get acquainted with PracMLN, and select areas for optimisation. The profiles inserted in this blog post give a good idea about the evolution of the bottlenecks in PracMLN, and thus show the progress made so far and simultaneously point towards the work left to be done.
I have learnt a lot from this GSoC project. I am extrememly thankful to my mentor Daniel Nyga, to the Insitute of Artificial Intelligence, University of Bremen, and to Google for offering me this great opportunity. I hope my work over this summer is useful to the open source community (I assure you my changes haven’t done this).
{kind=link}
I would be very happy to hear your thoughts in the comments below, and if you are a future contributor with a question, please feel free to reach out. Cheers!