Speeding Up PracMLN
Aug 6, 2018 17:43 · 1068 words · 6 minute read
Upon further analysis of the profiles, I identified a few areas of PracMLN to focus on. This analysis and the resultant edits further sped up the code by ~15%. After much deliberation; the locations of interest were identified to be:
- the
_iterworldsfunction - general speedups across
fol.pyxandfuzzy.pyx - multiple
truthfunctions incommon.pyx
A Setback
So my first approach was to quickly type all the relevant variables, and commit my changes. I had been working on PracMLN for a few months now, and I got a little overconfident with my capabilities. While the code was still compiling, running it gave arcane errors.
Traceback (most recent call last):
File "test.py", line 119, in <module>
main()
File "test.py", line 116, in main
runall()
File "test.py", line 96, in runall
test_inference_smokers()
File "test.py", line 22, in test_inference_smokers
mln = MLN(mlnfile=pth, grammar='StandardGrammar')
File "base.pyx", line 97, in pracmln.mln.base.MLN.__init__
File "base.pyx", line 557, in pracmln.mln.base.MLN.load
File "base.pyx", line 742, in pracmln.mln.base.parse_mln
File "base.pyx", line 192, in pracmln.mln.base.MLN.predicate
File "base.pyx", line 224, in pracmln.mln.base.MLN.declare_predicate
AttributeError: 'pracmln.mln.mlnpreds.Predicate' object has no attribute 'name'
On the surface, this is an attribute error with a trivial fix. However, fixing it will only lead to another error …
Traceback (most recent call last):
File "test.py", line 8, in <module>
from pracmln import MLN, Database
File "/home/kaivalya/ ... /python3/pracmln/__init__.py", line 22, in <module>
from .mln.base import MLN
File "/home/kaivalya/ ... /python3/pracmln/mln/__init__.py", line 27, in <module>
from .base import MLN
File "base.pyx", line 32, in init pracmln.mln.base
File "mlnpreds.pxd", line 1, in init pracmln.mln.mrf
File "mlnpreds.pyx", line 25, in init pracmln.mln.mlnpreds
ImportError: cannot import name BinaryVariable
… and so, on and on it went. I was nowhere near completing my planned optimisations, and I didn’t even know how far I was from finishing them. Moreover, it was not possible to leave the gsoc18-cython branch in this state, as the code, far from running with speed and efficiency, wasn’t even running with correcness.
Branching
More drastic measures were required. At this point, I decided to undo all my commits from the week (thank Linus Torvalds for Git version control). I created three separate branches, and split my work across them. Special care had to be taken, when checking out between various branches, to recompile the code, and delete/recreate symlinks to the appropriate files.
I have now merged these branches into my main gsoc18-cython branch, and the resultant changes, together yield a further ~15% speedup.
iterworlds
To properly Cythonise and speed up iterworlds (from mrf.pyx), some other changes needed to be made too. Namely, util.py and mrfvars.py were converted into util.pyx and mrfvars.pyx respectively. This was done so that CallByRef() and MRFVariable() could be made into extension types. In fact, not doing this was responsible for causing many of the errors previously encountered.
Cythonising _iterworlds( ... ) was then trivial, and accomplished without major complications worth documenting.
truth
The various truth functions in logic module all accept a world parameter, representing (initially) the evidence presented to the Markov Logic Network. They then evaluate the truth or falsity of the particular Formula. While I successfully converted all of these to cython, there remain significant unresolved issues.
The first thing to note is that there are many of them. In the case of Enumeration-Ask, with the smokers and taxonomy tests I was running, particular ones may be more used than other, but this doesn’t generalise further - varying from task to task. Here are the all truth functions from common.pyx.
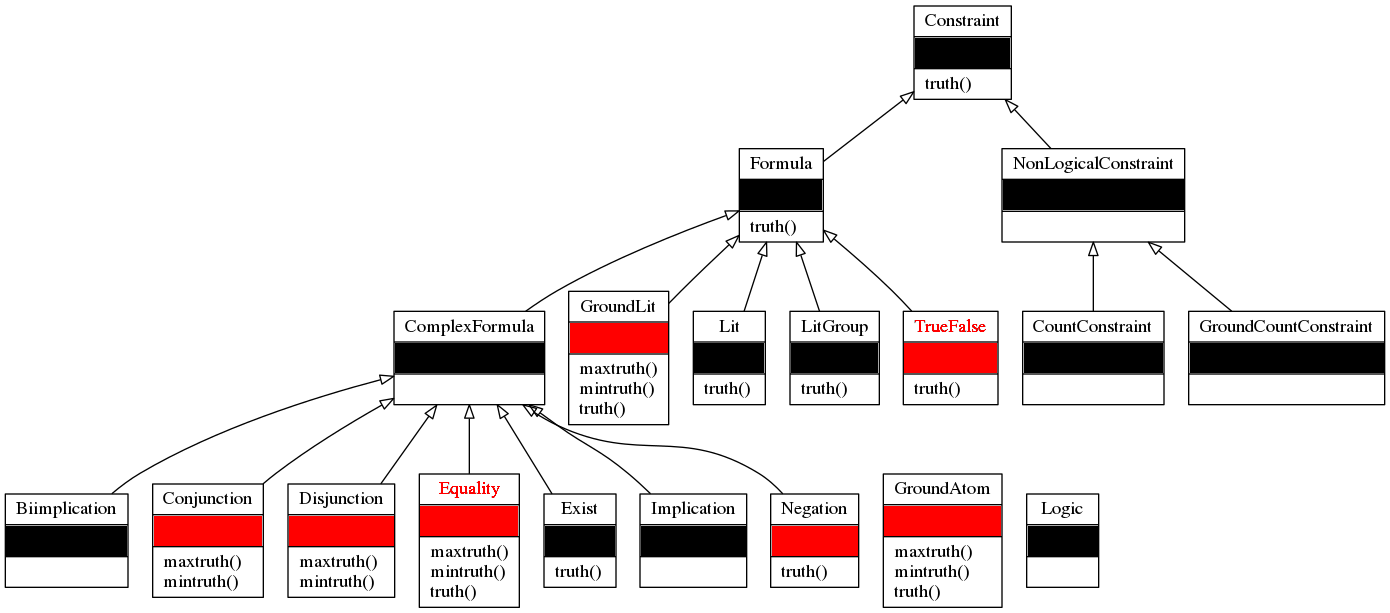
Truth Functions in the Logic Module
The funtions marked red in the figure above are the ones that are actually possible to optimise. Red text is used to indicate significant changes (in TrueFalse and Equality, respectively).
Another noteworthy thing is that many of these functions are trivial. They often have single statements:
def truth(self, world):
raise Exception("%s does not implement truth" % str(type(self)))
or
def truth(self, world):
return None
Not much optimisation possible here*!
Finally, the functions are all typed as cpdef. Unitl the cythonisation of PracMLN is complete, this needs to remain, since the functions are often called by python code. Performace can however be greatly improved if the functions can all by redifined with cdef.
*: This is technically untrue. If the functions could be typed as cdef, then they could make use of C inline functionality, essentially making them as fast as macros. This would provide a tremendous speed gain, but would be possible only once all calling code is Cythonised.
fol.pyx and fuzzy.pyx
The primary objective here was to speedup the entire logic module - including code beyond common.pyx. If you recall from one of my previous posts, converting FirstOrderLogic and FuzzyLogic to extension types is not possible. This was because the inner classes defined here made use of Python multiple inheritance - not permitted in Cython at all.
Daniel helped me overcome this problem - I redefined the class hierarchies entirely, getting rid of the multiple inheritance. It turns out, the second parent of the classes was redundant anyway, as it was already an ancestor. Consider the following example, with multiple inheritance, for Disjunction, along with the refactored version - utilising only single inheritance, but with identical functionality.
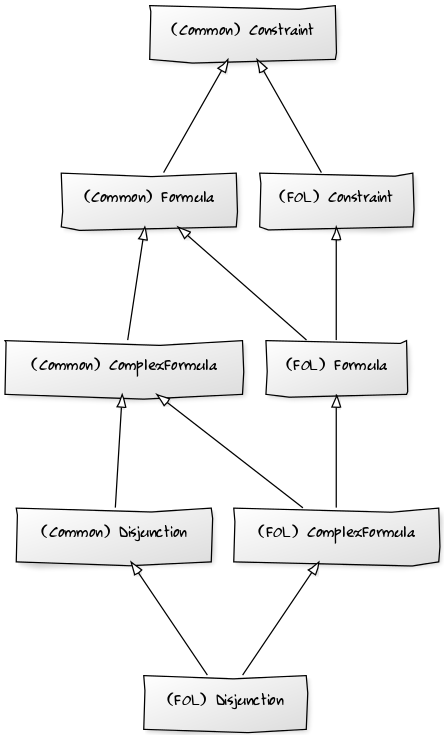

Inheritance Diagrams for FOL Disjunction
Once this refactoring was done, the inner classes were moved outside, just like in common.pyx, and FirstOrderLogic and FuzzyLogic were promptly converted to extension types.
Merging and Testing
With work on these branches complete, each was tested in isolation, and any remaining bugs were resolved. The branches were then all merged into the gsoc18-cython branch, and the code was profiled once again. Another speedup of ~15% was found. Thus the total speed gains stand at ~25%.
It is worth noting the inherent inaccuracy of these timing estimates here. Runtime fluctuates widely (atleast on my machine), and it is extremely difficult to control for background processes and other tasks when runnning such a significant, time-sensitive test. This problem can be mitigated by measuring runtime multiple times, and comparing averages, however this is an extremely slow process, since each pair of runs can take more than 15 minutes at a time.
The good news is that, despite all this, a very significant speedup has been achieved. Moreover, this speedup (while tested only for Enumeration-Ask) should hold for all PracMLN algorithms. The majority of the edits made over the course of this project were made to the common areas of the code - affecting all learning and inference algorithms.